


Codec: Execution Layer for AI-Powered Robotics - What You Need to Know
Rise of Robotic Agents, Codec VLAs, Operators, & More
Codec is building an execution layer for AI agents and robotics on Solana that goes beyond basic LLM wrappers. Rather than relying on static bots, Codec Operators are intelligent agents powered by Vision-Language-Action (VLA) models designed not just to reason but to act. These Operators form the foundation of a new workforce with machines that perceive their environment, reason through complex instructions, and physically execute tasks across digital and real-world interfaces.
In today’s edition, we explore how Codec leverages Solana’s high-throughput to deploy these adaptive agents at scale, the unique value of its Operator marketplace and compute fabric, and examine why VLAs unlock capabilities that pure LLM models cannot deliver.
Stay informed in the markets ⬇


Introduction to Codec Operators
The key to Codec’s thesis is that LLMs can explain a task but are not able to do it. VLA models solve this as they understand visual context and act on it without relying on hardcoded paths or external vision stacks.

Vision-Language-Action models integrate three functions: visual perception, language understanding, and structured action output into a single forward pass. Unlike LLMs that describe what should happen, VLAs emit coordinates, control signals, or executable commands to make it happen.
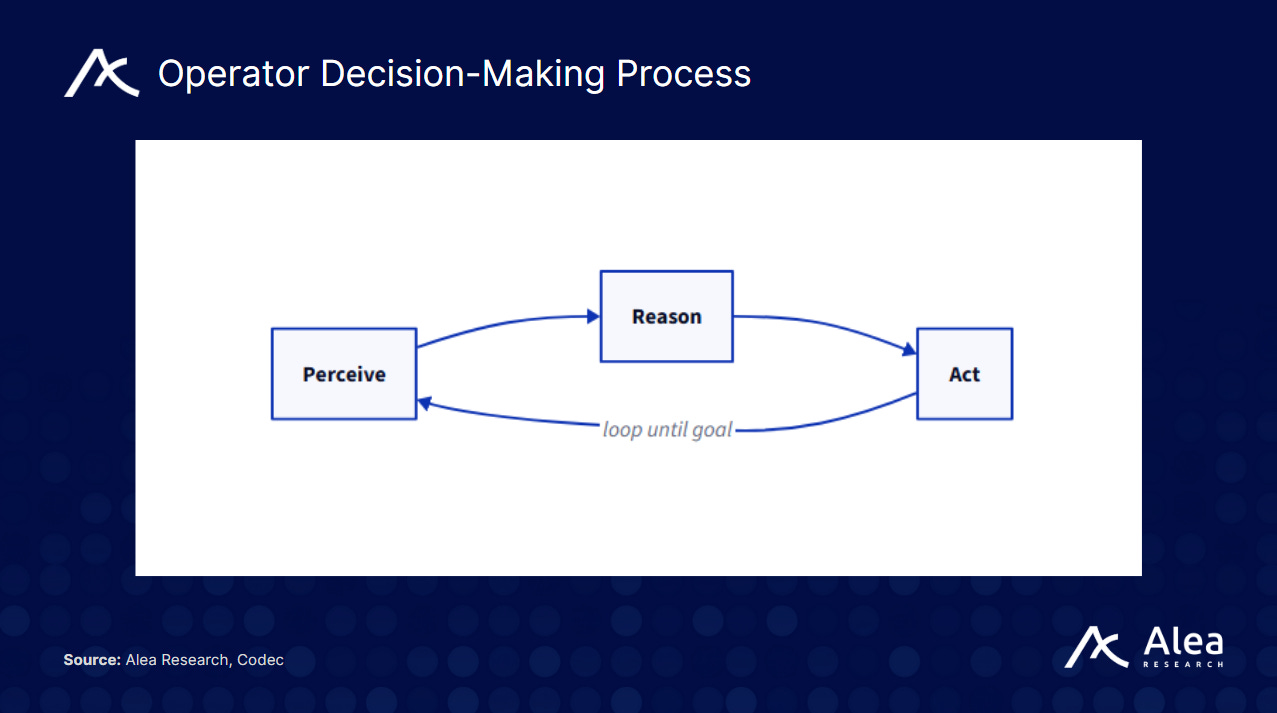
Each Operator runs a continuous loop:
Perceive: Capture screenshots, video feeds, or sensor data.
Reason: Process that context alongside natural-language prompts using a VLA model.
Act: Execute the resulting decisions through UI clicks or hardware control.
This allows Operators to autonomously navigate interfaces, adapt to visual changes, and handle exceptions in real time. In practice, that means a robotic arm can sort irregular parts without breaking, or a calendar bot can book meetings no matter the layout.
Codec Infrastructure Stack
At the core of Codec’s platform is a vertically integrated architecture designed to make autonomous AI agents not only intelligent, but deployable, responsive, and safe across both digital and physical systems.
This stack is built around three key layers:
Machine Layer: This is where Operators are deployed, trained, and executed. Each Operator runs inside a virtual environment offering near bare-metal performance with VM-level isolation which combines the performance of local execution with the security of full process containment.
System Layer: This layer sits above the machine layer. It enables real-time two-way interaction between deployed Operators and their execution environments. Using a low-latency WebRTC pipeline, Codec streams high-resolution desktop visuals or live camera feeds directly to the Operator in real time, enabling visual grounding for decision-making. Simultaneously, it injects precise inputs into those environments through their abstraction layer which translates model outputs into actionable mouse movements, keypresses, or robotic commands.
Intelligence Layer: This layer houses the Operator’s decision-making. It is lightweight VLA model embedded directly within each deployed agent. Unlike large LLMs that rely on off-device cloud calls, VLAs are designed to run fully locally. So, instead of sending data (e.g. screenshots, video, text instructions) to an LLM or VLA hosted on OpenAI, AWS, or a third-party inference provider, Codec ships the model with the Operator. Running it locally means lower latency, more reliability, greater security and the ability to run offline.
Training an Operator: From Demo to Deployment
Training Operators on Codec is designed to serve both non-developers and engineers. In the no-code path, a user simply demonstrates the task by clicking through a workflow while the system records the screen and captures each input. The Codec platform then fine-tunes the embedded VLA model based on this demo, using self-supervised learning to augment and reinforce understanding.
For developers, Codec offers SDKs that enable structured training: uploading datasets, composing workflows, and writing logic for edge cases. Fine-tuned models can be updated incrementally, allowing iterative development of robust, generalizable agents. This dual-mode makes Operator creation accessible while still offering programmability for more sophisticated tasks.
End Product
Simply put, Codec is a way to turn AI into workers, rather than text-generating LLMs. Codec enables agents that can see, understand, and act across both screens and real-world hardware, on tasks ranging from automating desktop tasks, piloting robots, or processing factory footage to control machinery.
The best way to view this is as the “Windows” operating system for AI automation. You could use Codec to automate a PDF processing flow on your laptop, or to manage entire fleets of sorting bots in a warehouse.
A recent example involves Robomove, their recent interactive robot playground that livestreams robots in action using a Unitree G1 humanoid robot.

What makes Codec crypto-native is its onchain coordination where each Operator can be published, reused, or composed into bigger workflows. Every contribution and usage tracked and rewarded via the $CODEC token (tokenomics yet to be released). This turns automation from a private tool into a public resource where anyone can build an Operator, anyone can run one, and the infrastructure to support it scales horizontally through decentralized compute and open economic incentives.
Important Links

Become a Premium member today to unlock all our research & reports.
Join thousands of sharp crypto investors & traders by becoming a Premium Member & gain an edge in the markets. For just $149/month, you can access our full suite of offerings:
Gain access to Deep Dives, Blueprints, Perspectives, Theses, Benchmarks & Outlooks.
Weekly market update reports and key actionable insights, keeping you informed as the market evolves.
Full access to historical research archive, including hundreds of long-form reports.